概要
RAG(Retrieval-Augmented Generation)のテストとして、LangchainのWikipedia Retrieverを試してみました。
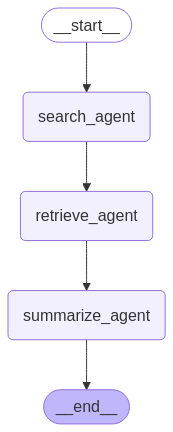
作成するエージェントワークフロー
Wikipedia検索を活用した漫画推薦AIを構築します。ユーザーの質問をもとに検索クエリを生成、Wikipediaから関連情報を取得し、得られた情報をもとに回答文を生成する仕組みです。
システムはsearch, retrieve, summarizeの3つのエージェントで構成します。
ライブラリ
- "langchain (>=0.3.20,<0.4.0)",
- "langchain-community (>=0.3.19,<0.4.0)",
- "wikipedia (>=1.4.0,<2.0.0)",
- "langchain-openai (>=0.3.8,<0.4.0)",
- "langgraph (>=0.3.5,<0.4.0)"
コードの全体像
コード全文
from typing import TypedDict
from langchain_community.retrievers import WikipediaRetriever
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langgraph.graph import StateGraph, END, START
from langgraph.checkpoint.memory import MemorySaver
import time
# ✅ 状態を定義するクラス
class RecommendationState(TypedDict):
question: str
search_query: str
context: str
summary: str
# ✅ サーチエージェント
def search_agent(state: RecommendationState) -> RecommendationState:
search_prompt = ChatPromptTemplate.from_template(
"""
あなたは与えられた情報をもとに、拡張検索生成のクエリを設計するエキスパートです。
以下のユーザーの質問をもとに、ユーザーがどのような要望・趣味嗜好を持っているかを考えて、クエリを設計してください。
余計な情報を含めず、最大3つまでのクエリのみを返してください。それぞれのクエリは必ず「カンマ区切り」で分離させてください。
また、「人気」「おすすめ」などの抽象的なクエリは除外してください。
漫画作品が検索されるように、クエリ内に「漫画」や「アニメ」などのキーを含めてください。
ユーザーの質問: {question}
"""
)
llm = ChatOpenAI(model="gpt-4o-mini")
chain = search_prompt | llm | StrOutputParser()
search_query = chain.invoke(
{
"question": state["question"],
}
)
return {**state, "search_query": search_query}
# ✅️ Wikipediaレトリバー
retriever = WikipediaRetriever(
lang="jp",
)
def retrieve_agent(state: RecommendationState) -> RecommendationState:
search_querys = state["search_query"].split(",")
# クエリを検索する
context = ""
for i, query in enumerate(search_querys):
docs = retriever.invoke(query)
# 検索が終了するまで待機
elapsed_time = 0
while (not docs) and (elapsed_time < 10):
time.sleep(1) # wait
elapsed_time += 1
print(i, elapsed_time)
# レトリバーの検索結果を結合
page_content = [
f"Title: {docs[0].metadata['title']}\nContent: {doc.page_content}\n\n"
for doc in docs
]
# クエリごとの結果を追加していく
context += "\n\n".join(page_content)
return {**state, "context": page_content}
# ✅️ サマリーエージェント
def summary_agent(state: RecommendationState) -> RecommendationState:
summary_prompt = ChatPromptTemplate.from_template(
"""
あなたはユーザーの質問に対し、与えられた情報をもとに適切な回答文を生成するエキスパートです。
以下の質問、検索結果をもとに回答を作成してください。
具体的な作品情報(タイトル、概要、推薦ポイント)を含めて、それぞれの作品を推薦してください。
ユーザーの質問:{question}
検索結果:{context}
"""
)
llm = ChatOpenAI(model="gpt-4o-mini")
chain = summary_prompt | llm | StrOutputParser()
summary = chain.invoke(
{
"question": state["question"],
"context": state["context"],
}
)
return {**state, "summary": summary}
# ✅ グラフを作成する
graph = StateGraph(RecommendationState)
graph.add_node("search_agent", search_agent)
graph.add_node("retrieve_agent", retrieve_agent)
graph.add_node("summarize_agent", summary_agent)
graph.add_edge(START, "search_agent")
graph.add_edge("search_agent", "retrieve_agent")
graph.add_edge("retrieve_agent", "summarize_agent")
graph.add_edge("summarize_agent", END)
checkpointer = MemorySaver()
graph = graph.compile(checkpointer=checkpointer)
# グラフの可視化
graph_image = graph.get_graph(xray=True).draw_mermaid_png()
with open("graph.png", "wb") as f:
f.write(graph_image)
# ✅ 実行
config = {"configurable": {"thread_id": "1"}}
result = graph.invoke(
{"question": "甘酸っぱい胸キュンな恋愛漫画が読みたいです。"},
config=config,
)
# ✅ 結果
# 最終結果を出力
print(result["summary"])
# チェックポイントを出力
for state in graph.get_state_history(config):
print(state.values, "\n")
解説
ステートの定義
各エージェントが共通して参照できる状態をRecommendationStateとして定義します。
この情報をエージェント間でパスし、随時読み込んだり書き換えたりすることができます。
class RecommendationState(TypedDict):
question: str
search_query: str
context: str
summary: str
検索エージェント(search_agent)の定義
ユーザーの質問から、最大3つまでの検索クエリを生成します。
プロンプトは以下のようにしています。ここでは検索クエリを一つの文字列に纏めるために、カンマ区切りなどの制約を入れています。
def search_agent(state: RecommendationState) -> RecommendationState:
search_prompt = ChatPromptTemplate.from_template(
"""
あなたは与えられた情報をもとに、拡張検索生成のクエリを設計するエキスパートです。
以下のユーザーの質問をもとに、ユーザーがどのような要望・趣味嗜好を持っているかを考えて、クエリを設計してください。
余計な情報を含めず、最大3つまでのクエリのみを返してください。それぞれのクエリは必ず「カンマ区切り」で分離させてください。
また、「人気」「おすすめ」などの抽象的なクエリは除外してください。
漫画作品が検索されるように、クエリ内に「漫画」や「アニメ」などのキーを含めてください。
ユーザーの質問: {question}
"""
)
llm = ChatOpenAI(model="gpt-4o-mini")
chain = search_prompt | llm | StrOutputParser()
search_query = chain.invoke(
{
"question": state["question"],
}
)
return {**state, "search_query": search_query}
情報取得エージェント(retrieve_agent)の定義
生成された検索クエリをもとに Wikipediaから情報を取得します。
取得した情報は検索結果ごとに結合し、次のエージェントへ渡します。
retriever = WikipediaRetriever(
lang="jp",
)
def retrieve_agent(state: RecommendationState) -> RecommendationState:
search_querys = state["search_query"].split(",")
# クエリを検索する
context = ""
for i, query in enumerate(search_querys):
docs = retriever.invoke(query)
# 検索が終了するまで待機
elapsed_time = 0
while (not docs) and (elapsed_time < 10):
time.sleep(1) # wait
elapsed_time += 1
print(i, elapsed_time)
# レトリバーの検索結果を結合
page_content = [
f"Title: {docs[0].metadata['title']}\nContent: {doc.page_content}\n\n"
for doc in docs
]
# クエリごとの結果を追加していく
context += "\n\n".join(page_content)
return {**state, "context": page_content}
回答生成エージェント(summary_agent)の定義
取得した情報を元に、ユーザーの質問に適した回答を生成します。
def summary_agent(state: RecommendationState) -> RecommendationState:
summary_prompt = ChatPromptTemplate.from_template(
"""
あなたはユーザーの質問に対し、与えられた情報をもとに適切な回答文を生成するエキスパートです。
以下の質問、検索結果をもとに回答を作成してください。
具体的な作品情報(タイトル、概要、推薦ポイント)を含めて、それぞれの作品を推薦してください。
ユーザーの質問:{question}
検索結果:{context}
"""
)
llm = ChatOpenAI(model="gpt-4o-mini")
chain = summary_prompt | llm | StrOutputParser()
summary = chain.invoke(
{
"question": state["question"],
"context": state["context"],
}
)
return {**state, "summary": summary}
LangGraph を用いたワークフローの構築
LangGraph を使用してエージェントを順序立てて実行するワークフローを定義します。
graph = StateGraph(RecommendationState)
graph.add_node("search_agent", search_agent)
graph.add_node("retrieve_agent", retrieve_agent)
graph.add_node("summarize_agent", summary_agent)
graph.add_edge(START, "search_agent")
graph.add_edge("search_agent", "retrieve_agent")
graph.add_edge("retrieve_agent", "summarize_agent")
graph.add_edge("summarize_agent", END)
checkpointer = MemorySaver()
graph = graph.compile(checkpointer=checkpointer)
実行
グラフに質問文を投入します。
# ✅ 実行
config = {"configurable": {"thread_id": "1"}}
result = graph.invoke(
{"question": "甘酸っぱい胸キュンな恋愛漫画が読みたいです。"},
config=config,
)
# ✅ 結果
# 最終結果を出力
print(result["summary"])
結果
以下のような結果が得られました。
甘酸っぱい胸キュン恋愛漫画をお探しのあなたには、以下の作品をおすすめします。
### 1. **「恋は雨上がりのように」**
**概要**: この作品は、17歳の女子高生あきらと、彼女がアルバイトをするファミレスの店長である45歳の男性との年の差恋愛を描いた物語です。あきらの恋心や成長が繊細に描かれ、多くの甘酸っぱい瞬間が魅力です。
**推薦ポイント**: 主人公のあきらが時折見せる純粋さや、年齢差を越えた恋愛模様が心にじんわりと響きます。特に彼女の小さな努力や気持ちの変化が丁寧に描かれており、読み終わった後はほっこりとした気持ちになれるでしょう。
---
### 2. **「俺物語!!」**
**概要**: 高校生の剛田猛男は、ブサイクだが心は優しく、家族思いの男の子。その一方で、彼には憧れの女子・砂川梓がいました。しかし、彼に好意を寄せる同級生が現れ、三角関係が展開します。
**推薦ポイント**: コメディ要素を含みつつも、猛男の純粋な想いと、友達との絆が描かれた作品です。特に恋愛模様が面白く、時に胸がキュンとしながらも、笑いを誘うシーンが満載です。心温まる友情と恋愛のストーリーに胸が躍ること間違いなしです。
---
### 3. **「青空エール」**
**概要**: 高校の野球部でパワフルな応援をする女子高生と、野球部のエースピッチャーとの青春ラブストーリーです。夢に向かって突き進む2人の姿が爽やかに描かれています。
**推薦ポイント**: 青春と恋愛がリンクし、エネルギー溢れる応援シーンや、お互いに成長し合う様子が感動的です。甘酸っぱい恋の瞬間とともに、夢を追いかける姿勢が心に響きます。読んだ後に青春を思い出させてくれる作品です。
これらの作品は、それぞれ異なる恋愛の形を描きながらも、甘酸っぱい瞬間がふんだんに盛り込まれています。ぜひ読んで、心をキュンキュンさせてみてください!
まとめ
LangChain + LangGraphを用いてWikipediaをデータソースにしたRAGを構築しました。
一方で、最近のLLMは相当賢いため、今回題材にした漫画のような一般情報はすでに知っていることも多く、プロンプトチューニングを相当上手くやらないとRAGを組み込んだ効果は出てこないような印象も受けました。
実務でRAGや検索ツールを組み込む場合は、
- ハルシネーションのチェックのために、検索結果と照合したい
- 完全に社内に閉じた、非公開データを扱いたい
などのユースケースを設定する必要があると思いました。